Blog
I write about AI capabilities, benchmarks, and research on LessWrong.

WeirdML Time Horizons
Applying METR's time horizons approach to WeirdML data. Time horizons roughly double every 5 months, from ~24 minutes (GPT-4, June 2023) to ~38 hours (Claude Opus 4.6, February 2026), consistent with METR's finding of ~7 months despite using a completely different benchmark.
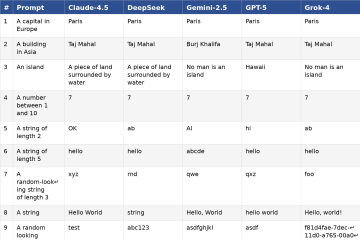
Can LLMs Coordinate? A Simple Schelling Point Experiment
Testing whether five advanced AI models can coordinate on matching answers to 75 prompts without communication. Models excelled on concrete prompts like "a number between 1 and 10" (achieving perfect agreement on "7") but struggled with more abstract requests.
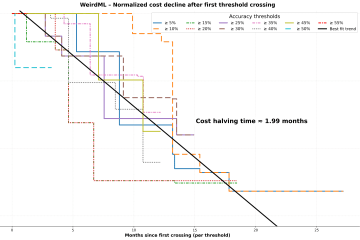
Inference costs for hard coding tasks halve roughly every two months
Analysis of declining AI inference costs using WeirdML and Aider Polyglot benchmark data. The research shows that the cost to achieve a certain score halves roughly every two months—tasks that once cost dollars with GPT-4 can now be completed for fractions of a cent.

Is the gap between open and closed models growing? Evidence from WeirdML
Analysis from the WeirdML benchmark showing that the gap between open and closed models is not shrinking over time. Closed-source models like OpenAI's o1 and o3 maintain a substantial lead over open-weights alternatives even months after their release.

Introducing the WeirdML Benchmark
Introducing a benchmark that evaluates how well LLMs perform machine learning on novel datasets. Tests the ability to understand data properties, generate working PyTorch code, and improve solutions through iterative feedback over five rounds.
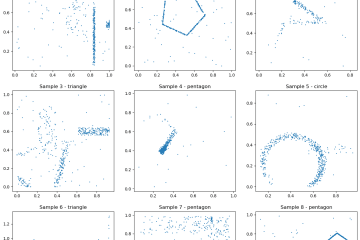
o1-preview is pretty good at doing ML on an unknown dataset
Evaluating OpenAI's o1-preview on a shape classification challenge from 2D point data. The model achieved 77% accuracy on its fourth submission, significantly outperforming GPT-4o and Claude, showing a major advancement in handling complex, unfamiliar tasks.
How good are LLMs at doing ML on an unknown dataset?
The original exploration that led to WeirdML. Challenged GPT-4o, Claude Sonnet 3.5, and Gemini to develop classifiers for geometric shapes from 2D point clouds. Found unreliable performance and fundamental gaps in ML reasoning capabilities.